Recently, I have been working for a subject storehouse system. Since duplicate subject are added to the storehouse, it is necessary to query the duplicate subject, and delete all duplicate subject leave only one, so that the duplicate subject cannot be taken when the test is taken.
First wrote a small example:
Single field operation
This is the table in the database:
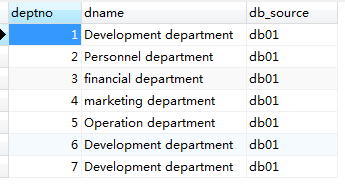
Group By:
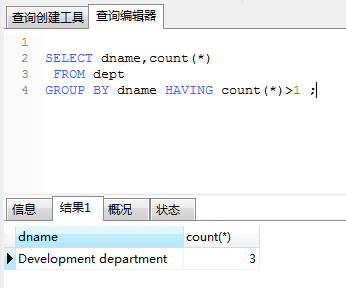
Select Repeat Field From Table Group By Repeat Field Having Count(*)>1See if there is duplicate data:
GROUP BY <column name sequence>
HAVING <group conditional expression>Query out: those groups that satisfy the group conditional expression (the number of repetitions is greater than 1) in the having clause according to the dname grouping
There is no difference between count(*) and count(1).
Query all duplicate data:
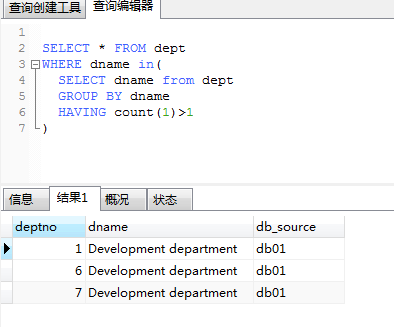
Select * From Table Where Repeat Field In (Select Repeat Field From Table Group By Repeat Field Having Count(*)>1)
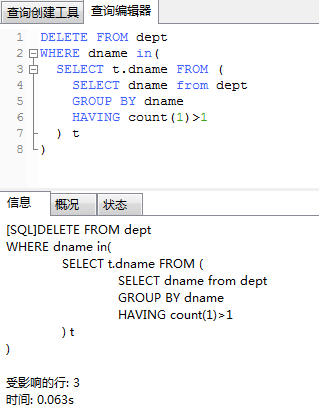
Delete all duplicate subject:
Change the above query select to delete (this will cause an error)
DELETE
FROM
dept
WHERE
dname IN (
SELECT
dname
FROM
dept
GROUP BY
dname
HAVING
count(1) > 1
The following error will occur: [Err] 1093 – You can’t specify target table ‘dept’ for update in FROM clause
The reason is: update this table and query this table at the same time, query this table and update the table, can be understood as deadlock. Mysql does not support this update to query the same table operation
Solution: Query the columns of data to be updated as a third-party table, and then filter the updates.
query duplicate subject in the table (according to depno, except for the one with the smallest rowid)
the first method:
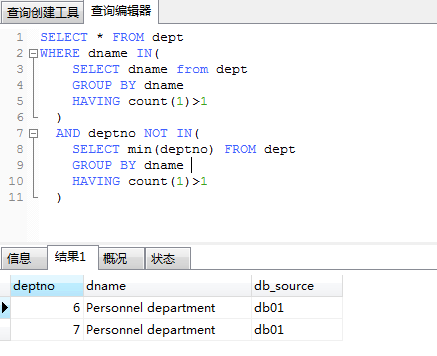
SELECT
*
FROM
dept
WHERE
dname IN (
SELECT
dname
FROM
dept
GROUP BY
dname
HAVING
COUNT(1) > 1
)
AND deptno NOT IN (
SELECT
MIN(deptno)
FROM
dept
GROUP BY
dname
HAVING
COUNT(1) > 1
)
The above is correct, but the query is too slow, you can try the following method:
The second method:
According to the dname grouping, find out the deptno minimum. Then query deptno and do not contain the one just found out. This will query all the duplicate data (except the smallest line of deptno)
SELECT *
FROM
dept
WHERE
deptno NOT IN (
SELECT
dt.minno
FROM
(
SELECT
MIN(deptno) AS minno
FROM
dept
GROUP BY
dname
) dt
)Delete redundant duplicate subject in the table and leave only one:
the first method:
DELETE
FROM
dept
WHERE
dname IN (
SELECT
t.dname
FROM
(
SELECT
dname
FROM
dept
GROUP BY
dname
HAVING
count(1) > 1
) t
)
AND deptno NOT IN (
SELECT
dt.mindeptno
FROM
(
SELECT
min(deptno) AS mindeptno
FROM
dept
GROUP BY
dname
HAVING
count(1) > 1
) dt
)The second method (corresponding to the second method of query above, just change select to delete):
DELETE
FROM
dept
WHERE
deptno NOT IN (
SELECT
dt.minno
FROM
(
SELECT
MIN(deptno) AS minno
FROM
dept
GROUP BY
dname
) dt
)Operation of multiple fields:
If you already have been learn to delete a single field is there, multiple fields are also very simple.
DELETE
FROM
dept
WHERE
(dname, db_source) IN (
SELECT
t.dname,
t.db_source
FROM
(
SELECT
dname,
db_source
FROM
dept
GROUP BY
dname,
db_source
HAVING
count(1) > 1
) t
)
AND deptno NOT IN (
SELECT
dt.mindeptno
FROM
(
SELECT
min(deptno) AS mindeptno
FROM
dept
GROUP BY
dname,
db_source
HAVING
count(1) > 1
)
to sum up:
In fact, there are still a lot of things to optimize in the above methods. If the amount of data is too large, the implementation is very slow. You can consider adding optimization:
Add an index to the frequently queried field
Change * to the field you need to query, don’t query it all out.
Small tables drive large tables with IN, large tables drive small tables with EXISTS. The case where IN is suitable is the case where the amount of external data is small, not the case where the external data is large, because IN will traverse all the data of the outer table, assuming 100 tables of a, and 10000 of b, the number of traversals is 100*10000 times, and exists Then, it is executed 100 times to judge whether the data in the a table exists in the b table, and it only executes the number of a.length. As for which efficiency is high, it depends on the situation, because in is compared in memory, and exists is the database query operation.